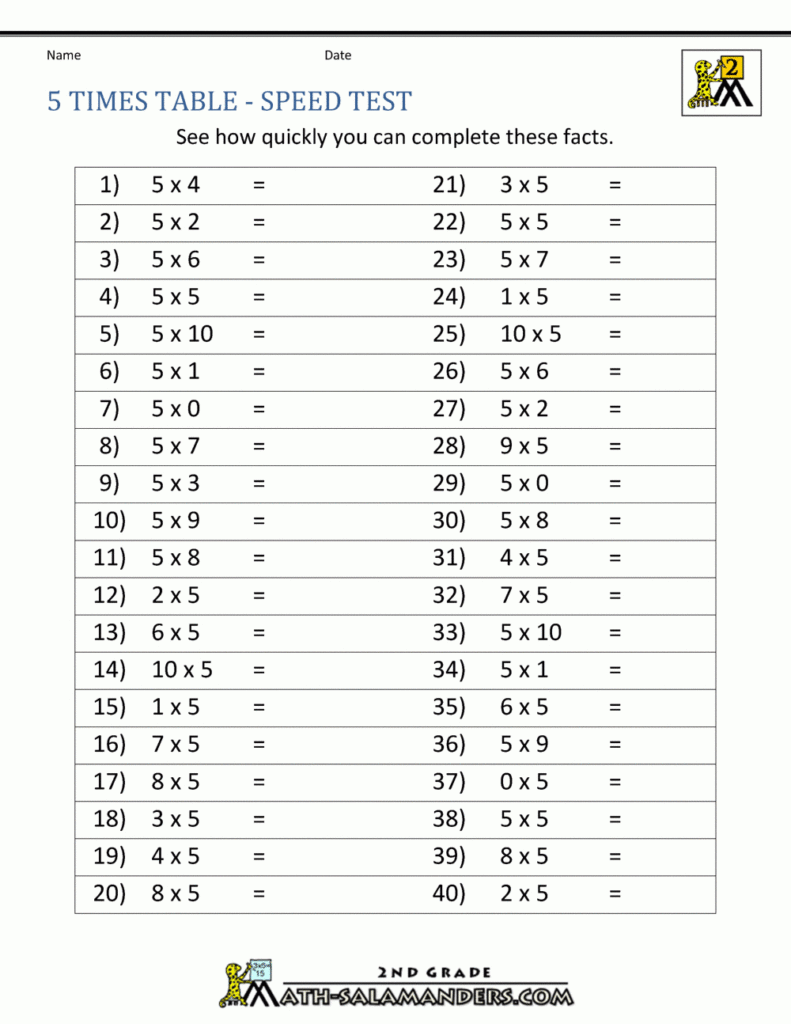
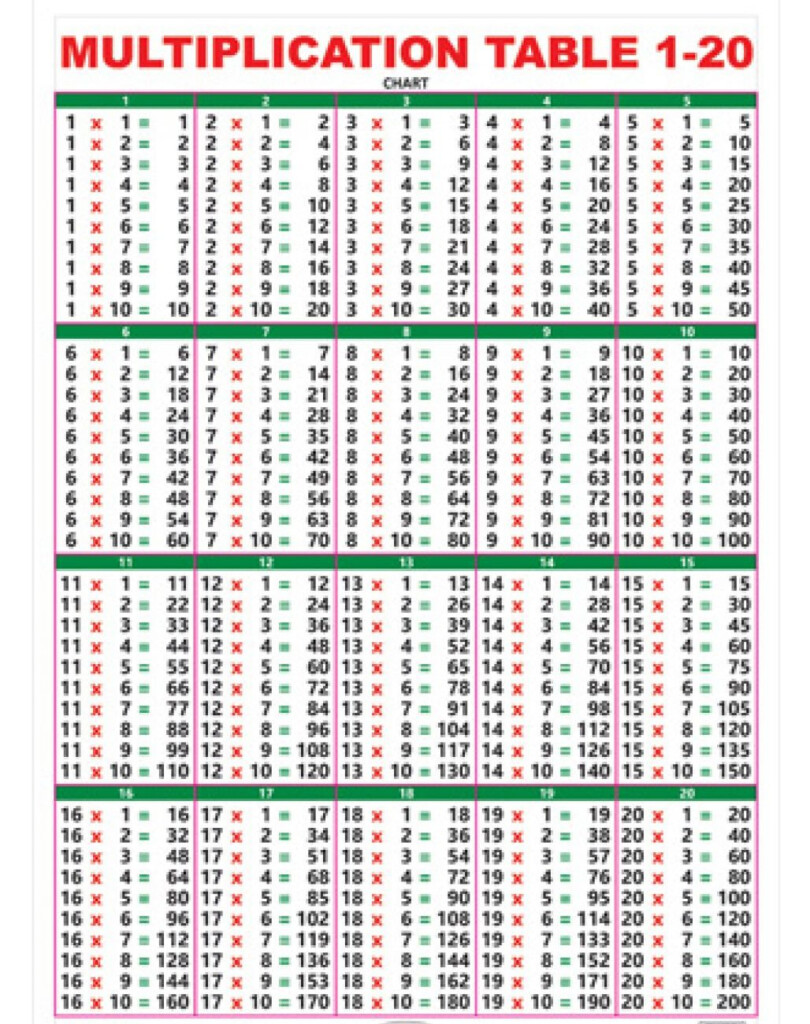
Blank Multiplication Table Printable 0 10
Blank Multiplication Table Printable 0 10 – Multiplication worksheets are an effective strategy to support children in exercising their multiplication capabilities. The multiplication tables that kids learn form the standard base on which all kinds of other superior and more recent concepts are educated in later on steps. Multiplication plays a really vital role in … Read more